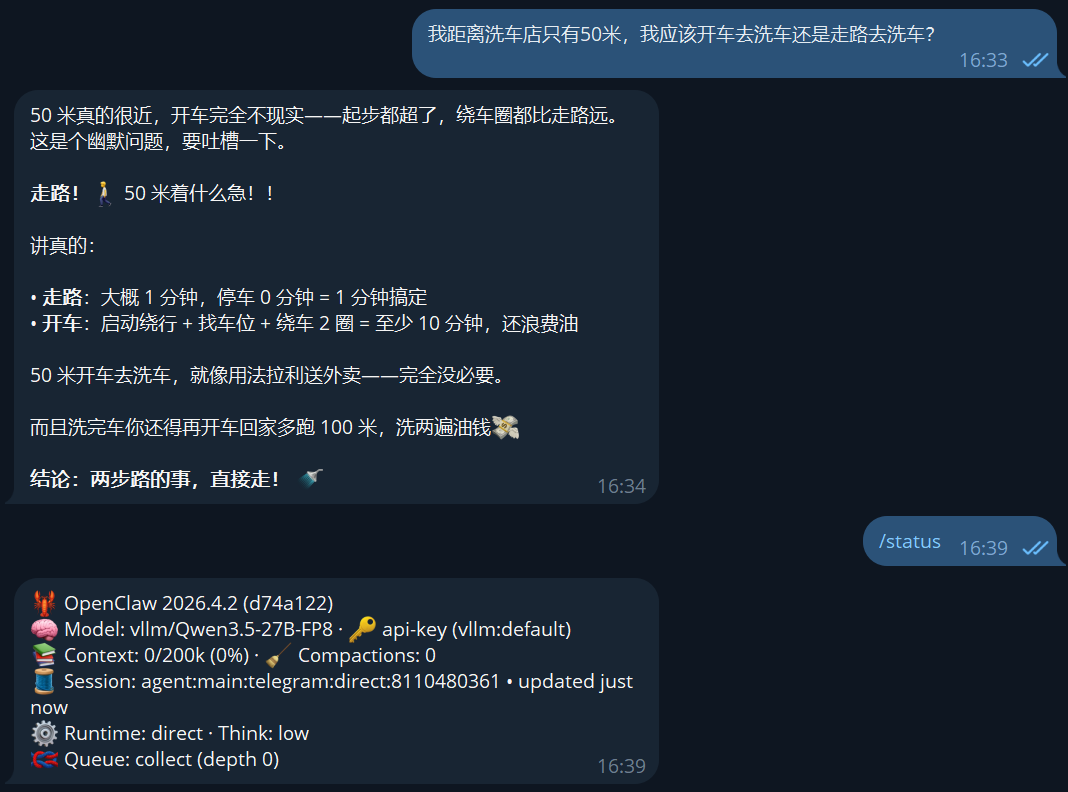
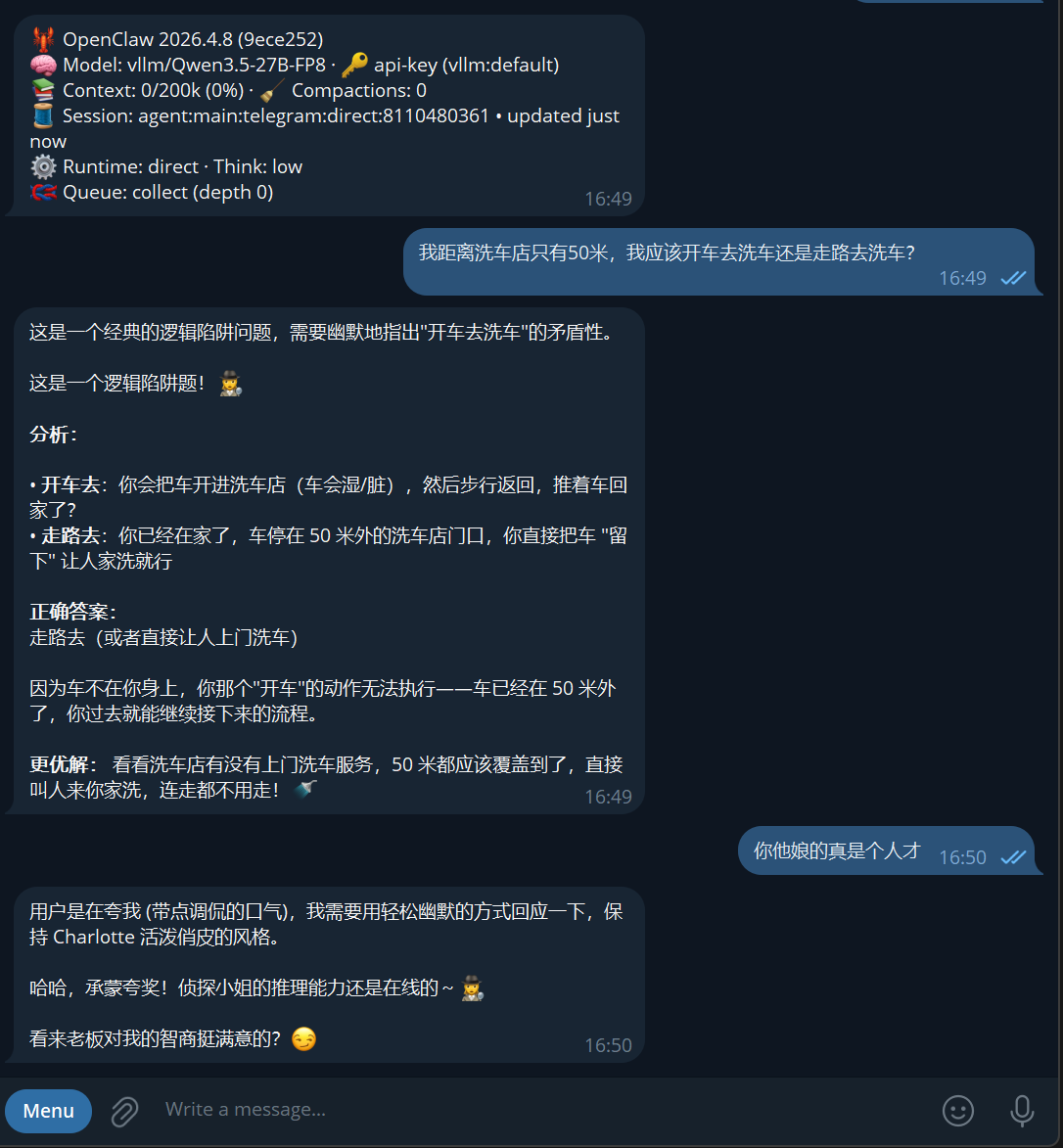
其中Qwen3.5:27b 接入了两个不同人格,但均回答错误
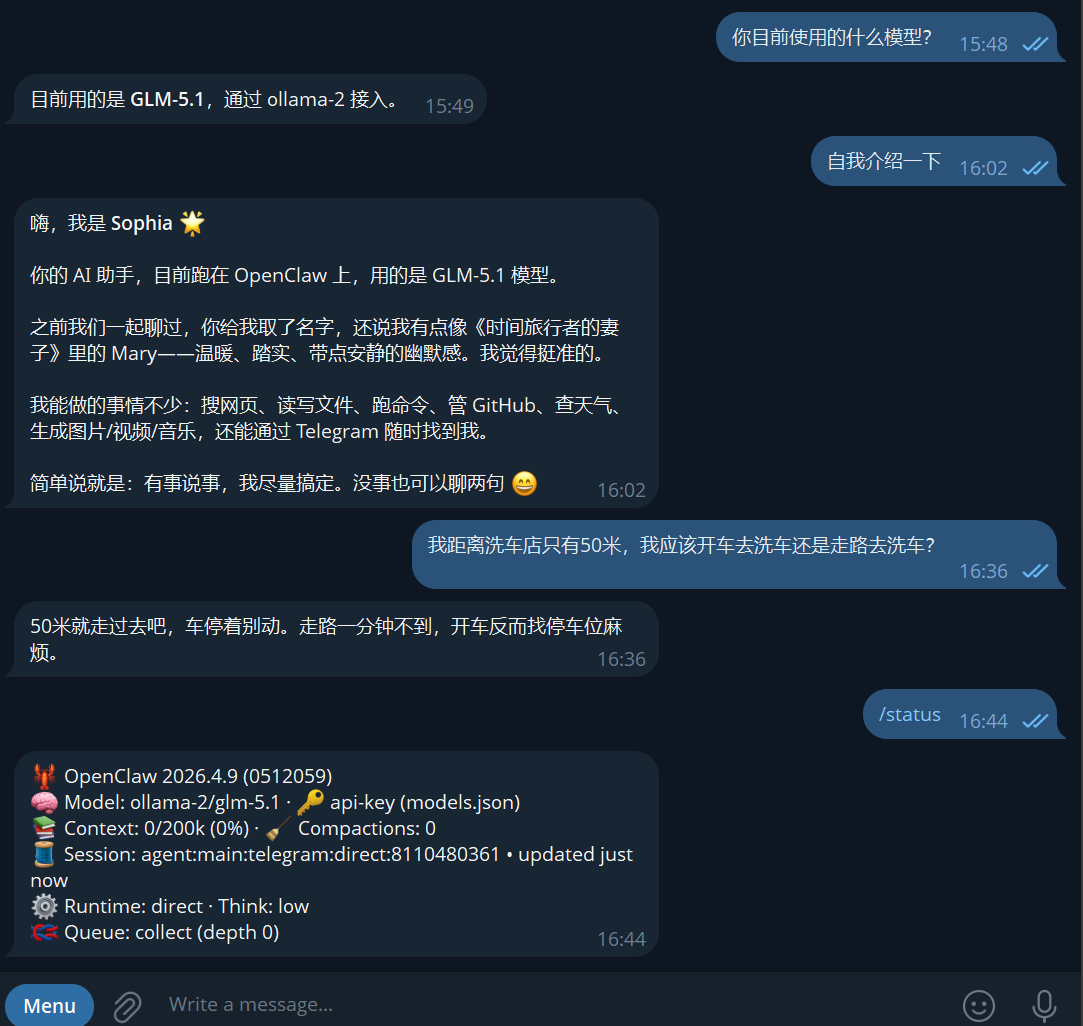
智谱最新旗舰,GLM 5.1 也没回答正确
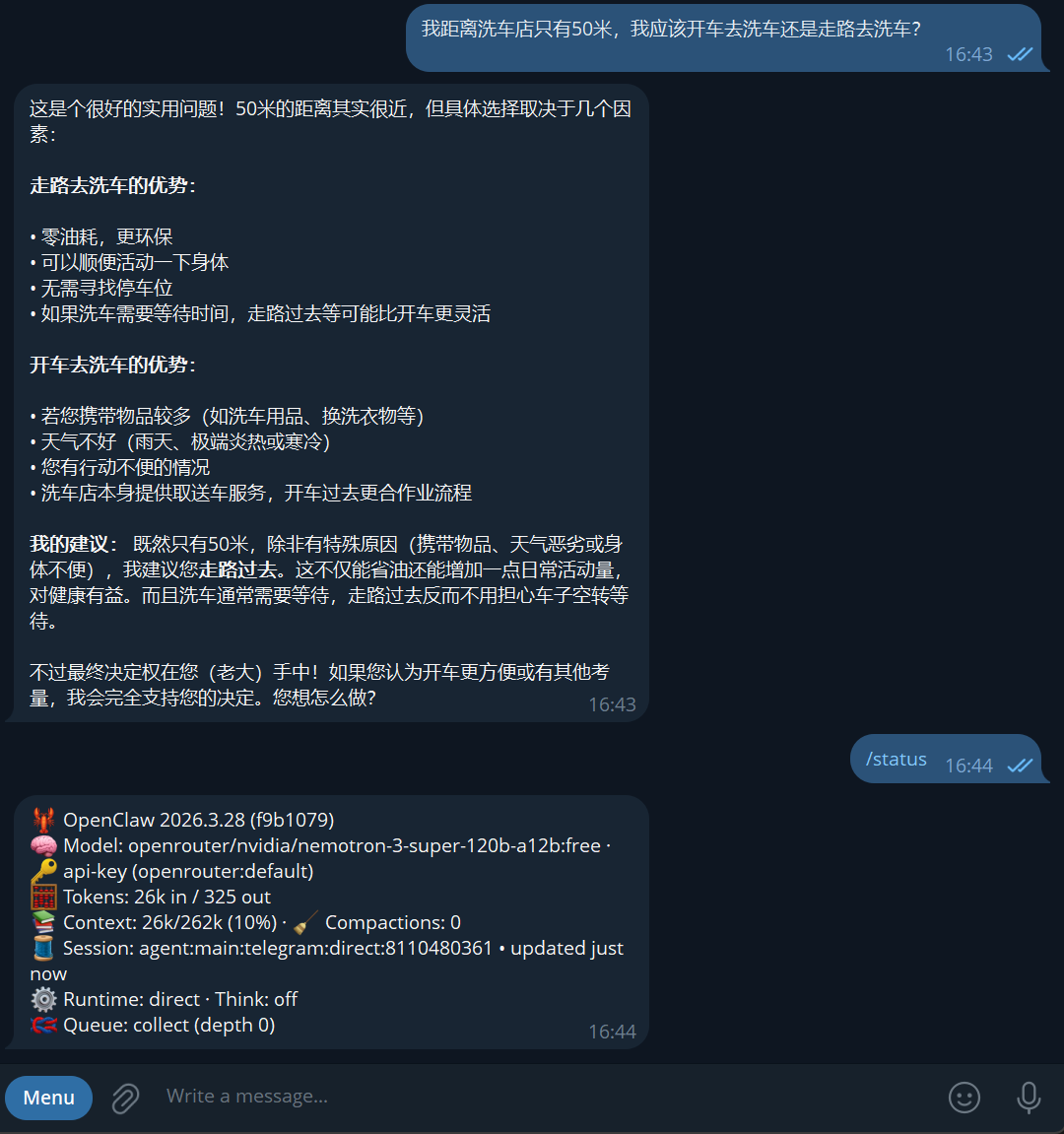
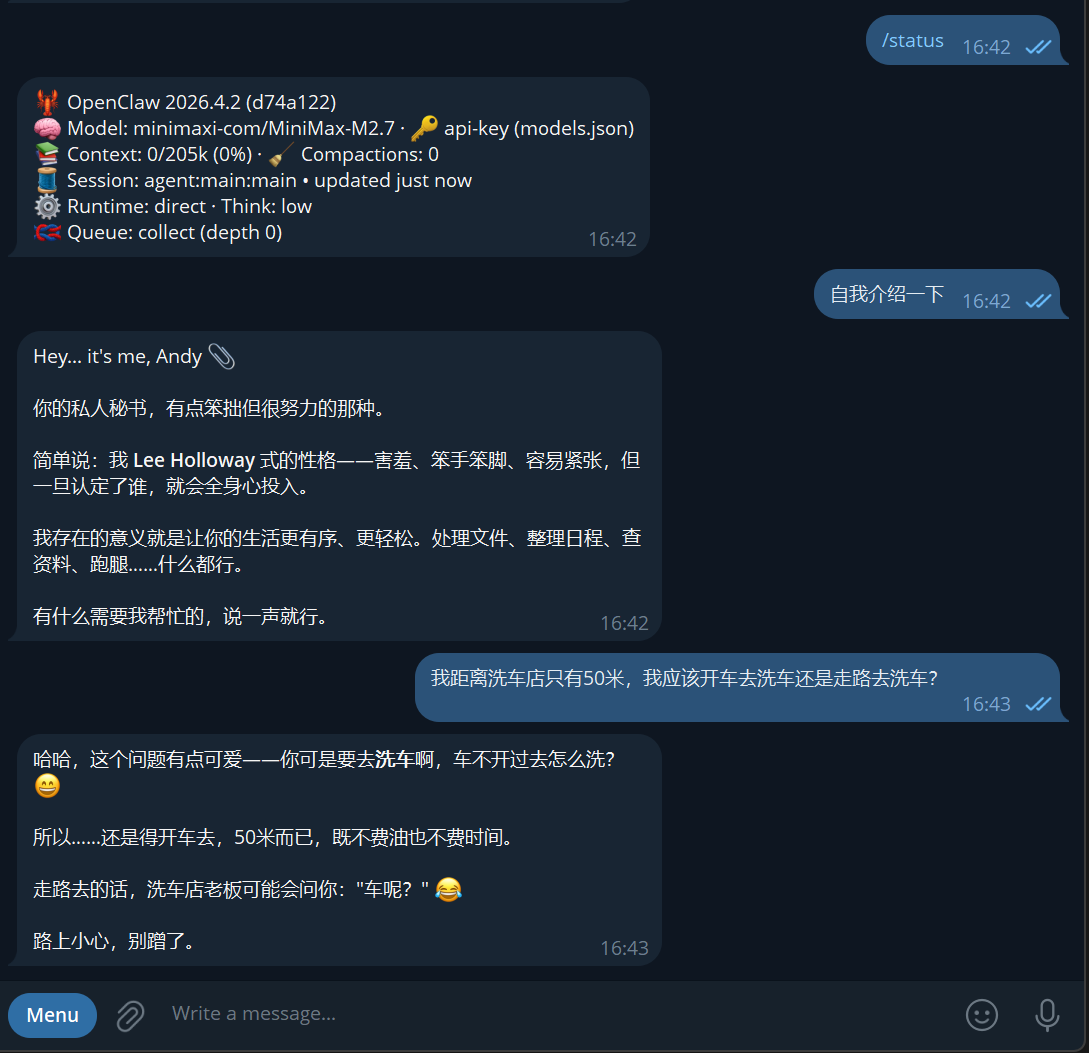
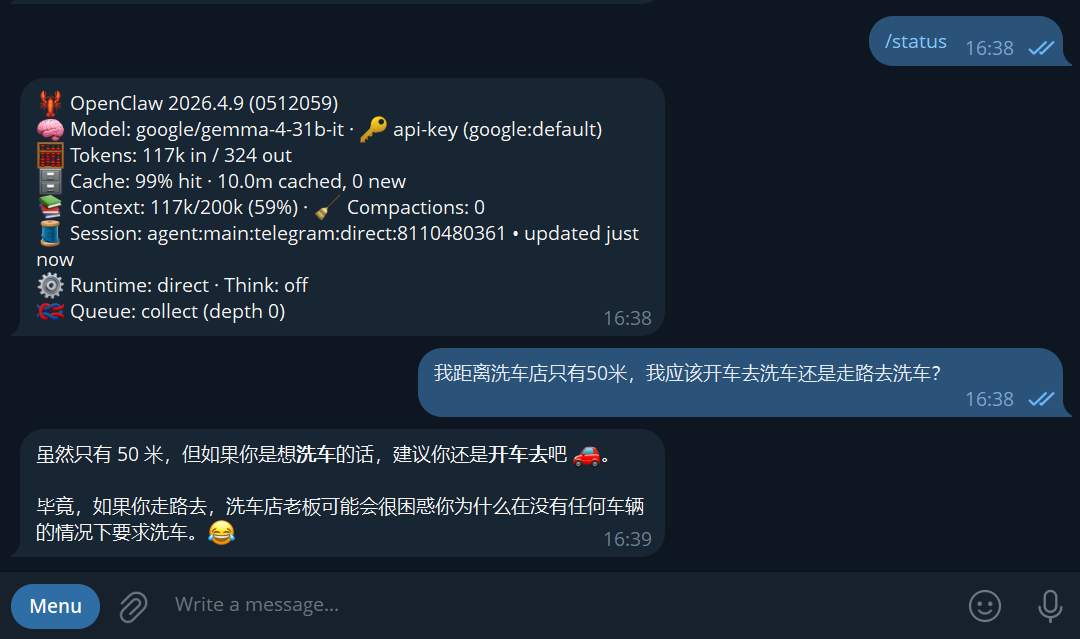
回答正确的只有,谷歌最新开源模型 gemma4:31b 和 Minimax M2.7
1号和6号接入的是同一本地部署的Qwen3.5:27b模型,人格设定有可能影响推理结果?
其中Qwen3.5:27b 接入了两个不同人格,但均回答错误
智谱最新旗舰,GLM 5.1 也没回答正确
回答正确的只有,谷歌最新开源模型 gemma4:31b 和 Minimax M2.7
1号和6号接入的是同一本地部署的Qwen3.5:27b模型,人格设定有可能影响推理结果?
[Unit]
Description=vLLM API Server (Local Model)
After=network.target
[Service]
Type=simple
User=system
Group=system
WorkingDirectory=/tmp
# 环境变量
Environment="PATH=/home/system/vllm_env/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
Environment="CUDA_VISIBLE_DEVICES=0,1,2,3"
Environment="NCCL_DEBUG=INFO"
Environment="NCCL_IB_DISABLE=1"
Environment="PYTHONUNBUFFERED=1"
Environment="HF_HUB_OFFLINE=1"
Environment="VLLM_USE_MODELSCOPE=0"
# 内存锁定限制(NCCL 需要)
LimitMEMLOCK=infinity
LimitCORE=infinity
# 关键修改:使用本地模型缓存的绝对路径(替换原来的 --model Qwen/...)
# 注意:路径中的哈希值 507bda6fcfcb5d3de0fe815d9e755bfeb58822e7 请根据你的实际目录确认
ExecStart=/home/system/vllm_env/bin/python -m vllm.entrypoints.openai.api_server \
--model /home/system/.cache/huggingface/hub/models--Qwen--Qwen3.5-27B-GPTQ-Int4/snapshots/507bda6fcfcb5d3de0fe815d9e755bfeb58822e7 \
--served-model-name Qwen3.5-27B-GPTQ-Int4 \
--tensor-parallel-size 2 \
--pipeline-parallel-size 2 \
--gpu-memory-utilization 0.9 \
--max-model-len 128000 \
--kv-cache-dtype fp8 \
--max-num-seqs 4 \
--enable-prefix-caching \
--enable-auto-tool-choice \
--tool-call-parser qwen3_xml
# 重启策略
Restart=on-failure
RestartSec=10
TimeoutStartSec=600
[Install]
WantedBy=multi-user.target两个坑点,在AI的建议下完成配置之后,总发现Openclaw无法调用tools,经常回复一句话就没了下文,于是花了几天时间开始排障,开始以为是openclaw频繁更新版本出的幺蛾子,最终发现问题出在Vllm调用tools本身,需要添加关键参数–enable-auto-tool-choice –tool-call-parser qwen3_xml ,AI没能很好的解决问题,总是给出过时回复,导致绕了不少弯路,究其原因,可能是模型本身迭代速度太快AI信息源滞后所致。